Plan library
All of the plans documented in this section can be downloaded and then imported into your own private instance by following this procedure.
Basics
Here are a few basic, yet non-trivial plans which will help you get started with the most useful and common constructs. We will be practicing with a very simple source type called “Json String”, which will help us distribute data across iterations and threads.
Following a predefined convention, we can pass an arbitrary table of data provided in the Json format and then access that table line by line.
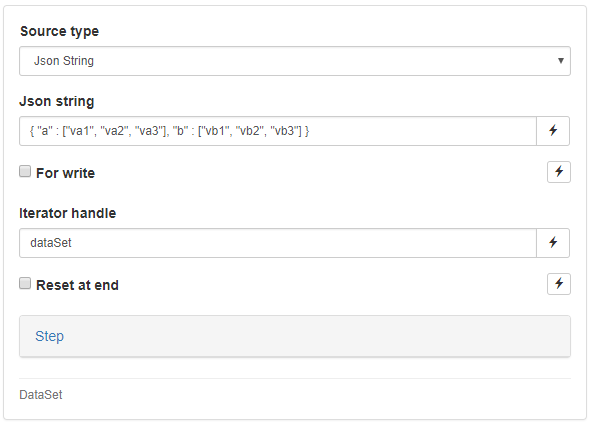
Example 1: DataSet & While
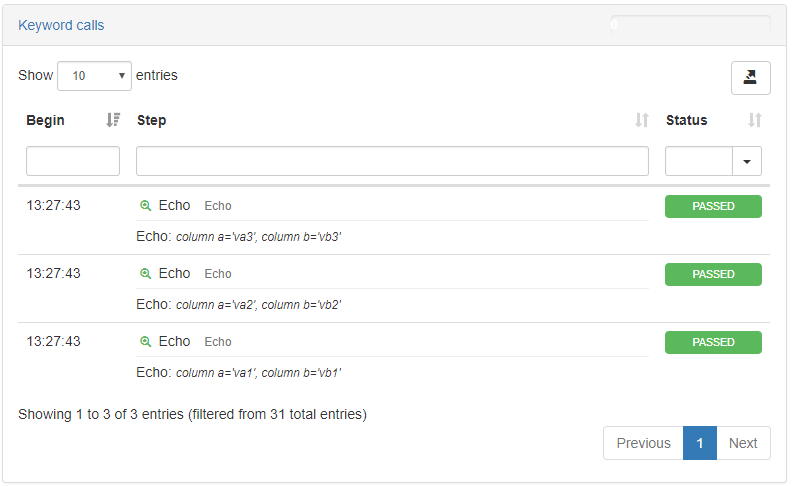
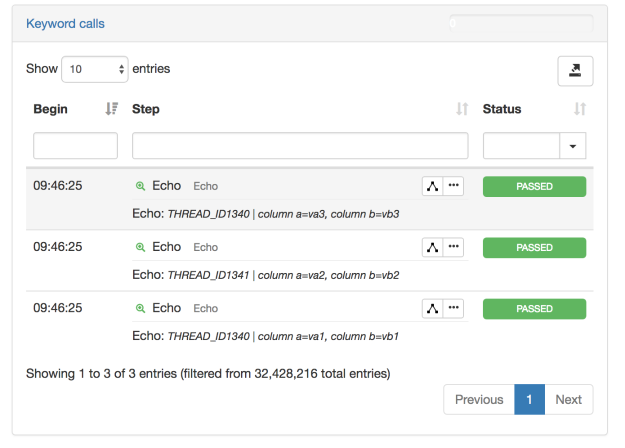
The first test plan we recommend importing and executing showcases the ability to iterate over a dataset and access each line until the dataset runs out of data. We will also display the content of the two columns of each row as we iterate.
Download plan: DataSet_while.json
The result should look like this:
Example 2: DataSet & For with reset
In certain situations, you will want to iterate more than once over your dataset. To achieve this, you need to check the box “Reset at end” on the configuration screen of your dataset, and then simply call next() a larger number of times than the dataset’s size (i.e than the number of lines in the dataset). This will cause for the dataset to reset to its initial state. This can happen as many times as you wish.

Download plan: DataSet_withReset.json
This is how your dataset will look after you’ve imported it:
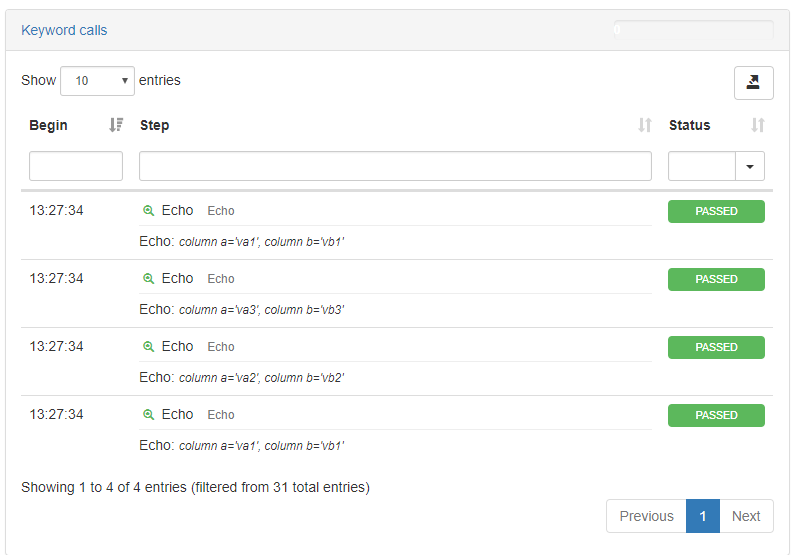
You will now see in the execution results that calling next() a fourth time will cause for the first row to be read again:
Load
In this category, we’ve gathered Load oriented plans. They’re usually driven at high level by parameters such as concurrency and duration. These plans use datasets as a mean to generate realistic transactions but in general, the user doesn’t really care about the exact input combinations being used or how many times they were used.
Example 1: ThreadGroup & DataSet
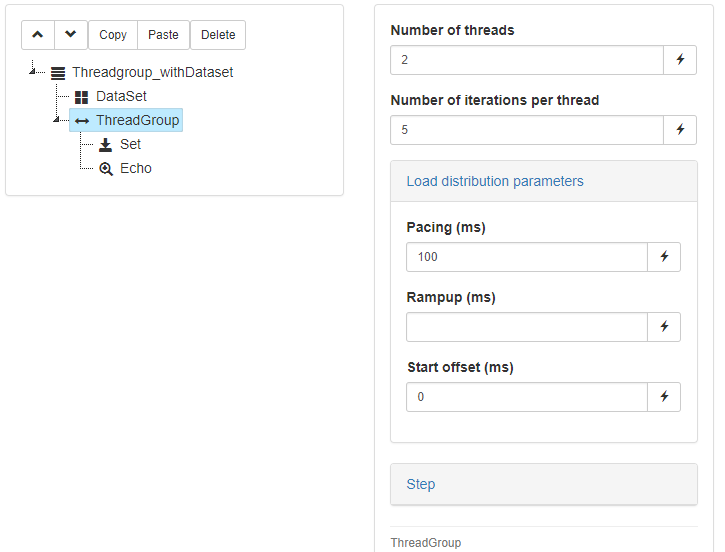
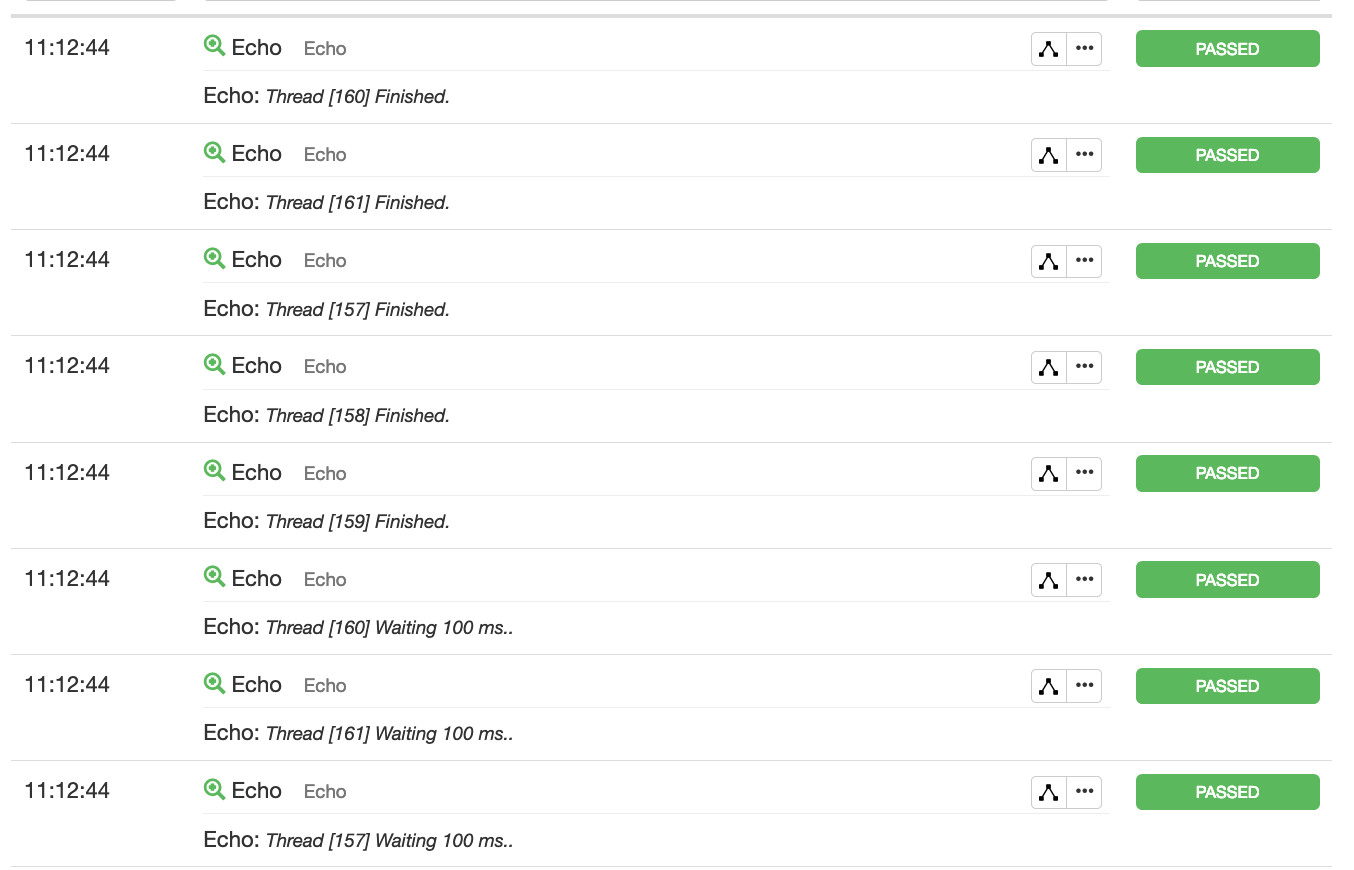
The following test plan builds on the idea of explicitly iterating over a dataset, and introduces threading. The content of the ThreadGroup node will be duplicated and immediately executed by each new thread. We will be setting additional load-specific parameters such as a number of threads, a number of iterations per thread and a pacing.
Download plan: ThreadGroup_withDataset.json
As you can see, the dataset is now being iterated in parallel, and yet safety is provided for the entire group of threads accessing it:
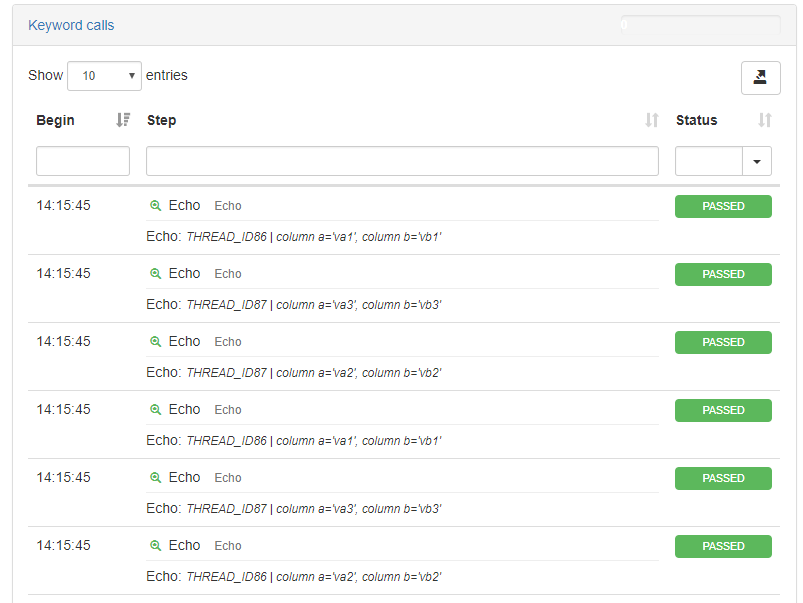
Watch out: there is no strong guarantee that the different threads will be executing every row in a strongly ordered manner. If a thread happens to be slightly quicker than the other, if might produce what seems like out-of-order row executions.
Data-Driven
In this category, we’ve gathered functional test plans. They usually aim at testing specific input combinations. In a data-driven context, the goal is to produce a transaction exactly once per test case (i.e input combination). Concurrency just helps decreasing the overall execution time, but in general, the user doesn’t care about exactly how long the test run lasted or what the exact throughput was.
Example 1: ForEach
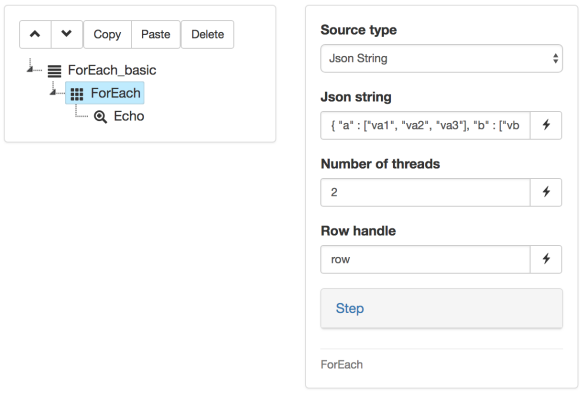
Similar to our use of the DataSet control with the while loop, it is possible to iterate one time and one time only over every row of a dataset by using the ForEach control, which implicitly already contains a dataset. You’ll see in this example that in scenarios where exhaustion of the dataset is required (no “Reset at end”), the use of the ForEach control greatly simplifies the syntax.
Download plan:Dataset_basic.json
Our ForEach node with only an Echo as its child, and DataSource declaration directly nested within the ForEach control:
The execution result:
Synchronization
In this category, we’ll take a look at synchronization techniques, artefacts and services
Example 1: Meeting point
This plan illustrates how to make use of the Synchronized artefact to implement a meeting point for multiple threads within a plan.
Plan name: SyncPlan
Download plan: meetingPoint.json
Monitoring
Attached in this category are a couple of pure groovy plans which can be used for monitoring the load on step’s agent grid and event broker. One can schedule these plans to run, for instance, every five minutes, and then chart the resulting data (i.e trends) in RTM.
Example 1: EventBroker persistent monitor
This sample plan reports the broker’s current storage size (i.e number of events present at that moment) and the size water mark (max size in the broker’s life span).
Example 2: Grid monitor persistent monitor
This sample plan reports the number of free tokens for each agent as an RTM transaction
Plan Modularity
In this category, we’re illustrating the different ways you can split a test plan into different modules.
Example 1: CallPlan strategy
We recommend using this strategy only when the child plan (callee) needs to directly access complex objects (for example, a DataSet), i.e it requires inputs that can not be serialized.
Advantages : easy and painless, allows for quick modularization of your plan content
Drawbacks : introduces white-box dependency, lacks clarity, as any parent plan will have to be aware of the specific context required by the child plan
Plan has yet to be uploaded.
Example 2: Composite Keyword strategy
We recommend using this strategy by default, as soon and as long as the child plan only requires serializable inputs (json types). In other words, no direct access to complex objects needs to be made in the parent plan.
Advantages : clear interface between caller and callee, the child plan is self-contained and can be used as a black box. It can be executed in isolation from the parent plan.
Drawbacks : direct exposure of complex objects like a DataSet is prohibited.
Plan has yet to be uploaded