TCO of Browser-based load testing
This article analyses and explains the total cost of ownership (TCO) of browser based load testing.
Written by Dorian Cransac
Introduction
For the last 25 years, in traditional IT environments, much of the load testing of web applications has been done at HTTP level and, often, E2E functional testing has been done manually through the use of a real browser. More recently, Selenium has emerged as an alternative way to automate web workflows by reproducing a real browser instance and interacting directly with elements present in web pages. This article looks at some of the benefits of this approach.
The experience of HTTP
Many users will have had experience with LoadRunner, JMeter, Gatling, Grinder or SoapUI / LoadUI.
For a long time, these highly serviceable tools were the only viable option for simulating user traffic at scale against web applications, with the main use case for them being load testing. Due in large part to the availability of low-priced commodity hardware and horizontally scalable, distributed computing platforms. In today’s environment, it is now technically possible to build large automation clusters for comparatively low cost as well.
Using the codebase
The ever-increasing complexity of frontend web frameworks and tasks handled by modern browsers makes creating and managing scripts exponentially difficult. One of the difficulties is that the number of request-response pairs increases substantially, and requests become progressively more difficult to differentiate and replay in a way that is logical to the server. Since many frameworks produce cryptic request headers, parameters, and contents, the resulting code becomes very difficult for users to read and understand without investing a lot of time in thorough debugging sessions and comparisons of HTTP logs. In addition to traditional HTTP scripts, new technologies such as WebSockets and Server-Sent Events introduce new protocols as well as asynchronous workflows, which are particularly difficult to script correctly, to the process. Eventually, the code base becomes too complex and cluttered and much of the code gets discarded. Users either cannot or do not take the time to properly understand it, modularize it and build a large component-oriented codebase. Often it is easier to just re-capture and redo the scripts at the beginning of each testing process. This method is less time-consuming than maintaining the existing code. To illustrate this point, the first codeblock is generated in the tool Grinder. The intent is to cause the browser to navigate to the homepage of Microsoft’s search engine, Bing.com, and retrieve all the data necessary to display the page as a normal browser would.
def createRequest(test, url, headers=None):
"""Create an instrumented HTTPRequest."""
request = HTTPRequest(url=url)
if headers: request.headers=headers
test.record(request, HTTPRequest.getHttpMethodFilter())
return request
connectionDefaults.defaultHeaders = \
[ NVPair('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Firefox/50.0'),
NVPair('Accept-Encoding', 'gzip, deflate'),
NVPair('Accept-Language', 'fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3'), ]
headers0= \
[ NVPair('Accept',
'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8')]
headers1= \
[ NVPair('Accept', '*/*'),
NVPair('Referer', 'http://www.bing.com/'), ]
headers2= \
[ NVPair('Accept',
'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'),
NVPair('Referer', 'http://www.bing.com/'), ]
url0 = 'http://bing.com:80'
url1 = 'http://www.bing.com:80'
request101 = createRequest(Test(101, 'GET /'), url0, headers0)
request201 = createRequest(Test(201, 'GET /'), url1, headers0)
request202 = createRequest(Test(202, 'GET hpc18.png'), url1, headers1)
request203 = createRequest(Test(203, 'GET bing_p_rr_teal_min.ico'), url1, headers0)
request301 = createRequest(Test(301, 'GET l'), url1, headers1)
request401 = createRequest(Test(401, 'POST lsp.aspx'), url1, headers2)
request402 = createRequest(Test(402, 'GET 8665a969.js'), url1, headers1)
request403 = createRequest(Test(403, 'GET 3adc8d70.js'), url1, headers2)
request404 = createRequest(Test(404, 'GET f1d86b5a.js'), url1, headers2)
request405 = createRequest(Test(405, 'GET 89faaefc.js'), url1, headers2)
request406 = createRequest(Test(406, 'GET 015d6a32.js'), url1, headers2)
request407 = createRequest(Test(407, 'GET ResurrectionBay.jpg'), url1, headers1)
request408 = createRequest(Test(408, 'GET d0c1edfd.js'), url1, headers1)
request409 = createRequest(Test(409, 'GET HPImgVidViewer_c.js'), url1, headers1)
#[...] (you get the point...)
Compare that to what is required for Selenium to produce the same result.
driver.get("http://www.bing.com");
Not only do the size and complexity of the code differ by several orders of magnitude, but the Selenium version is simple enough that no capture (or even maintenance effort in certain cases) is even needed!
The obstacle to generating a realistic load.
There are inherent obstacles to generating simulations. Issues can be missed in testing due to technical simplifications. Users can also generate false positives that only occur because of minute technical differences between the simulation and the real-world scenario. Since there is no efficient way for a real-world user to affect these problems, there is not a real need for this to be a concern, but that would not be found out until the results are fully analyzed. This adds unnecessary workload and lost time for the contributors involved with the project.
With the larger scope of responsibilities on the browser’s side, it is accurate to expect more difficulties to manage technical accuracy. The following are examples of technical details which can prove to have a huge impact on performance or even functional accuracy in production:
- Static resource caches
- HTTP/TCP connection lifecycles
- Request concurrency and timing
- Async and event-driven scenarios (SSE, WebSockets.)
- Security settings (authentication type, encryption, etc.)
There are many cases in which issues are detected in browser-based simulations which would have gone unnoticed if the simulation had been implemented at the HTTP level instead. There are also many instances in which users run into problems at the HTTP level which would not have occurred when using a browser.
The following illustrates the sequence of requests on the bing.com web page, captured with Chrome’s DevTools.
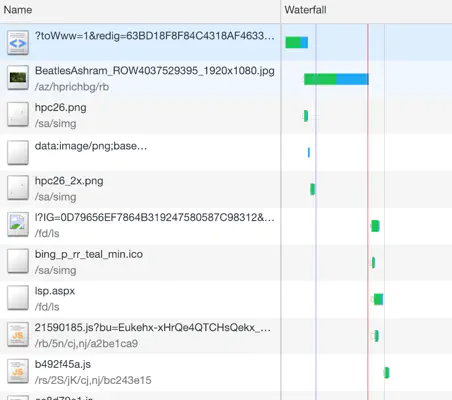
Up to 3 requests are being sent in parallel in this example, but many requests are also sent sequentially, with timings that may vary. Concurrency varies according to many factors and can get problematic at times.
User experience
When an HTTP simulation is run successfully, it is difficult to draw clear conclusions from the results regarding the quality of the experience, as perceived by the end-user. The response time of a request may match the amount of time that a real user would be waiting for, but in some cases, it does not match.
For example, a user could find that all of the individual requests are relatively fast, but when added up to reflect reality more accurately, the sequence as a whole is actually taking a longer time than desired. If the concurrency is not accounted for, the user could end up exaggerating the significance of the performance issue. This makes it difficult to determine meaningful SLAs on such low-level components. And even if that were doable, how many individuals in an organization are expert enough on the subject to understand the issues?
In a best-case scenario, there is still potential for mistaken analysis, since users are not accounting for JavaScript execution time. The order in which individual elements are loaded on the page, which elements are seen first by the user, or how long they will take to load once the raw data has been received by the client.
Here’s another view from Chrome’s DevTools which illustrates the complexity of the browser’s own stack:
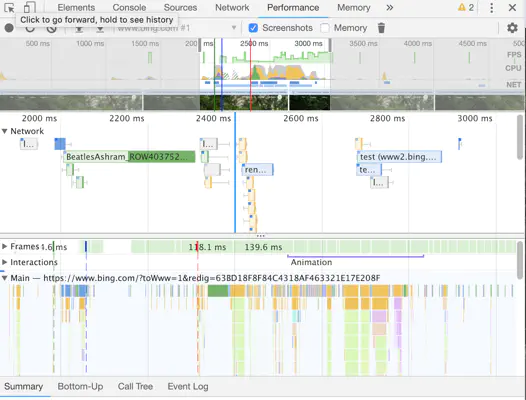
It is apparent that the amount of time spent in the network layer only accounts for some of the overall page load time. There are some gaps in the network view which have to be accounted for by other layers of code, such as JS execution time and rendering.
Users should also spend significant time investigating slow requests which are completely secondary because they are happening in the background and are not contributing directly to the end-users experience.
While the protocol-level simulation could be good enough for server-side testing, it suffers when asked to accurately reflect user experience.
The Browser Environment
This section examines the benefits of a browser-based simulation.
A cleaner API: WebDriver
Scripting becomes much simpler when using events and DOM elements than with HTTP requests and responses. HTTP requests carry information that is often difficult for users to read and manipulate and is laden with extraneous information and data.
The WebDriver API, which was originally provided with Selenium but has now expanded to a much broader context, exposes basic interactions with a browser, leveraging XPath to browse its tree of HTML elements (DOM).
Here is an example of what the API looks like (from Selenium’s documentation):
public class Selenium2Example {
public static void main(String[] args) {
// Create a new instance of the Firefox driver
WebDriver driver = new FirefoxDriver();
// And now use this to visit Google
driver.navigate().to("http://www.google.com");
// Find the text input element by its name
WebElement element = driver.findElement(By.name("q"));
// Enter something to search for
element.sendKeys("Cheese!");
// Now submit the form. WebDriver will find the form for us from the element
element.submit();
// Wait for the page to load, timeout after 10 seconds
(new WebDriverWait(driver, 10)).until(new ExpectedCondition() {
public Boolean apply(WebDriver d) {
return d.getTitle().toLowerCase().startsWith("cheese!");
}});
// Should see: "cheese! - Google Search"
System.out.println("Page title is: " + driver.getTitle());
//Close the browser
driver.quit();
}
}
Working directly with the browser also makes for much more concise code, as demonstrated in the earlier sections of this article. While it is possible to record scripts with tools such as Selenium’s IDE, in most cases, it is unnecessary. An experienced automation engineer will simply be able to code through a test scenario after looking at the API, which itself is extremely simple.
The required skill here is the ability to maintain and reuse code repeatedly, through multiple releases, and among common components across projects. Recording is a minor detail, as the desired result is to avoid having to repeat the steps every time something changes in the target application (the recording of the scenario itself but also all of the work that comes with it, such as input variabilization).
The runtime is a black box
All the low-level HTTP configuration and implementation details are now handled by the browser itself, making configuration easy. There is no need to consider resource caching, request concurrency, or any other technical detail. If it works in a user’s browser, it will work in the simulation. Users need to be diligent to re-use the specific browser instance simulating real-world applications.
Another benefit of the browser case is replay. Analyzing the HTTP logs to find correlation issues can be time-consuming; most HTTP tools either don’t support HTML visualization well or don’t support it at all. In either case, JavaScript code won’t be executed and the necessary information will be missing to accurately diagnose the issues in scripts. With browser emulation, the user receives instant replay with all the necessary information. There is also the ability to capture screenshots and send them back as part of the outputs of the script.
Real user experience
In a browser-based simulation, direct interactions with the web page’s elements and events allow for the definition of meaningful transactions. It is simple to understand SLA’s that are set with events visible to the user. This means that both the technical staff such as engineers, and developers, and non-technical staff such as business analysts, and other project stakeholders can communicate effectively when discussing NFRs.
Cross-browser testing
Using different browsers (and browser versions) may lead to different results for the end-user.

One of the advantages of using a library such as Selenium along with a full-blown browser instance is the ability to run the same collection of scripts and test scenarios across many different OS & browser stack combinations while performing deep checks on the client.
Without JavaScript code execution, most of the presentation and navigation issues would go unnoticed.
Exceptions
Plain HTTP(S) automation is still required from time to time; for instance, in integration testing in which users only want to run load against their server’s REST API and are not interested in simulating end-to-end scenarios.
Note: If using a tool such as Step, there is no need to choose between Selenium and HTTP libraries; in addition to full Selenium support, plugins that leverage the runtime libraries of certain legacy tools such as JMeter or SoapUI are provided. This allows the user to realize the advantages of both cases, using a lightweight scripting environment they might already be familiar with, and the benefits of the superior services provided by a modern solution like Step which includes workload distribution, central aggregation and archiving, and collaborative workflows, to name a few.
Breaking down the total cost of ownership (TCO)
This section discusses some of the most critical factors that drive costs.
Test code maintenance
Automation projects bring the same challenges as regular software projects, in the sense that they require the delivery, execution, and maintenance of distributed code.
Despite best efforts, applications will undergo last-minute changes, simulations will grow more complex, issues will be identified, and additional tests designed. As explained in the last section, managing the costs of test code maintenance is key and all these issues are simplified in browser-based automation.
The costs of creating and maintaining test code vary greatly based on several factors such as frequency of change, the complexity of the application, and the experience of the engineer. However, in the case of a moderately complex application, outcomes suggest that a switch from protocol-based to browser-based emulation can reduce costs.
Infrastructure
Hardware allocation can be a costly expense in many corporate environments. Even with the advent of virtualization, VMs are still costly. This consideration, along with a reluctance to change, is why some legacy tools are still popular. With a lower client footprint, hardware is not the main issue, it is normally the test code maintenance.
The trend is that hardware resources are becoming more cost-effective, and more so in the cloud. If a company’s in-house offering is unsatisfactory, connecting an external cloud-based test farm may not be as hard as it seems. Some organizations have had success connecting their cloud-based solutions to their client’s infrastructure, resulting in a hybrid testing environment. Cloud providers contribute to the reduction of infrastructure costs and so, it is becoming more and more common to see clients entirely rebuild their testing platform.
Tooling
Client code must be distributed across many hosts, and results have to be aggregated for analysis and then archived. Many previous existing tools are simply not capable of handling this workload.
Step is a language-agnostic automation platform designed from the ground up for scalability. It is compatible with libraries such as Selenium, and it takes care, of many of the responsibilities which would otherwise be the responsibility of the test engineers, such as central resource management, result aggregation, and archiving or real-time monitoring and reporting capability.
Crucially, elastic scalability with Step is simplified, as any number of agents can join and leave the automation grid at any point in time, even while a test is running.
Summary: This article analyses and explains the total cost of ownership (TCO) of browser based load testing.

This article documents how Exense automated and scaled complex Android scenarios for a large organization in Switzerland.

This article explains how automation as a service, as well as Step, can help companies improve their automation and developer efficiency.

In this short guide, we will learn to understand browser-based load-testing and its benefits.

This article demonstrates how Step can automate Microsoft software for the purposes of testing and general usage.

This article explains how Robotic Process Automation (RPA) was used to benefit an insurance company in Switzerland.

This article analyses different situations involving end-to-end testing and proposes automation and the Step platform as a viable solution.
Want to hear our latest updates about automation?
Don't miss out on our regular blog posts - Subscribe now!